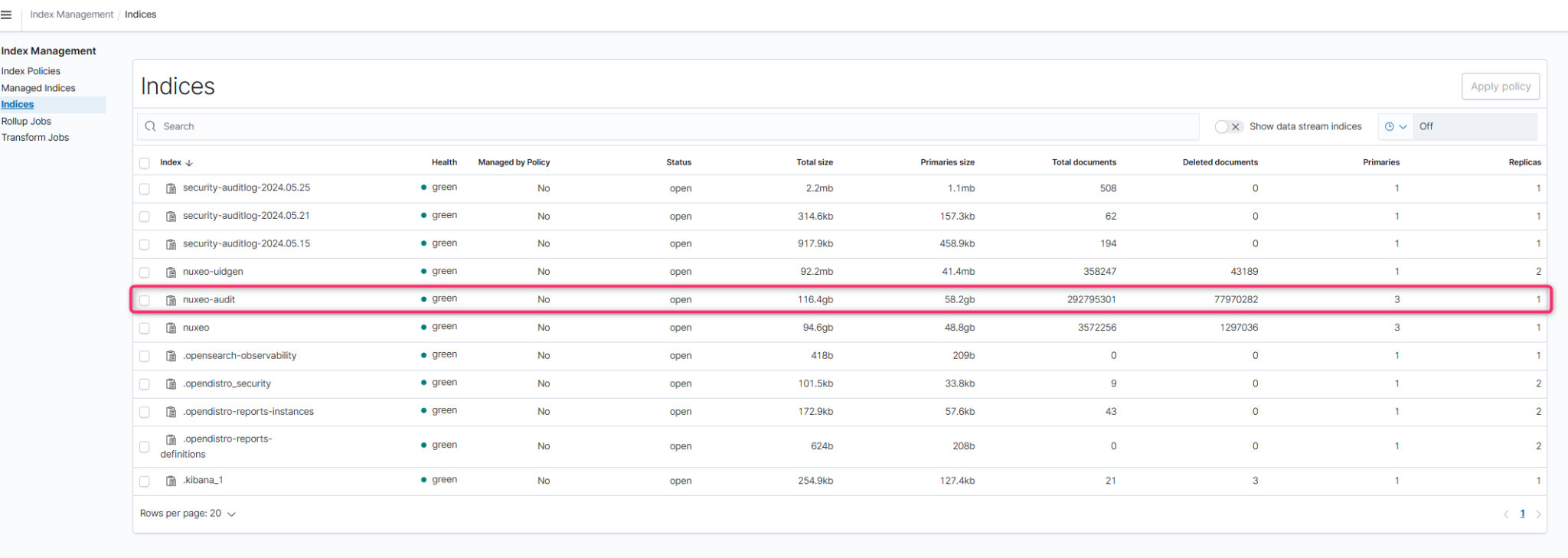
We are facing a major issue in our production environment regarding the index “nuxeo-audit” (and related indexes such as “nuxeo-uidgen” and “nuxeo”), which stores all audit events from our Nuxeo ECM platform.
Context:
Until recently, this index contained approximately 3 years of audit history. However, during a recent investigation we discovered that a large part of the historical audit data has disappeared. More specifically, almost all audit documents prior to May 2024 no longer appear in queries, even though they were previously available.
May 2024 is the date when our platform migrated from Elasticsearch to OpenSearch. Our initial working hypothesis was therefore that the migration process did not fully restore or reindex the historical audit data. However, our client provided evidence that in October 2024 (several months after the migration), the complete audit history for certain documents was still visible in OpenSearch Dashboards. This confirms that the data was present after the migration and has been lost at a later point in time.
Today, the index “nuxeo-audit” still shows ~3 billion documents, but around ~78 million documents are now marked as “deleted”, and almost all pre-May-2024 events are missing.
We are trying to understand:
Whether it is still possible to recover this missing audit data using our existing snapshots, and what is the recommended approach to restore or inspect past index segments.
Under which internal OpenSearch mechanisms (segment merging, corruption, forced recovery, accidental index recreation, etc.) millions of documents could be marked as deleted without any ILM policy attached.
What could cause such a massive and silent loss of indexed documents in OpenSearch, especially on an unmanaged index with no ILM and no DELETE operations executed by our team.
Any guidance or analysis from the OpenSearch community would be greatly appreciated.
@Riadh This seems to be a human error. I have never seen any documents marked as deleted automatically without some involvement from a human, ILM or Curator. If any of the primary shards were to fail, you would not see “deleted” as the result.
In regards to restoring from snapshot, How often do you snapshot this index? I would recommend to restore the snapshots gradually from May '24 and query the data using timestamps. This would at least give you an indication when these documents were deleted. There is no way to restore only a subset of documents from an index. You would have to restore the full index then reindex the necessary documents if needed.
Also do you still see documents getting marked as deleted, or this was a once off event? And lastly, did you upgrade from ElasticSearch directly to OS1.3.6, or there was another upgrade in between?
Thanks a lot for your detailed answer and clarifications.
To answer your questions:
We unfortunately do not have any old snapshots available for this index anymore.
On the OpenSearch cluster we only keep about 15 days of snapshots in the repository (local filesystem), so we cannot restore snapshots from May 2024 to track when the deletions started.
In May 2024, we performed a Nuxeo upgrade from LTS 2019 to LTS 2023 and, as part of this project, a migration from Elasticsearch to OpenSearch 1.3.6.
The nuxeo-audit index was reindexed from the old ES cluster to the new OS cluster using a _reindex command similar to:
- Our initial hypothesis was indeed that something went wrong during this _reindex operation and that part of the history was not properly copied.
However, our customer has provided evidence that on 10 October 2024 (about 4–5 months after the upgrade), they were still able to see the full audit history (including events prior to May 2024) for some documents in the UI.
This suggests that the history was present and usable after the migration, and that the loss of audit data is likely a later event.
On our side, we have done a deeper technical analysis of the current nuxeo-audit index:
A _count query on nuxeo-audit over the period 2020-01-01 → 2024-05-26 (range on eventDate) returns only 4,390 documents, whereas the index currently contains about 306,711,718 documents in total.
→ So less than 0.002% of the entries belong to the period before 26 May 2024, which is clearly incompatible with 3+ years of normal audit activity.
We checked the OpenSearch logs (including rotated .gz files) and did not find any explicit traces of:
DELETE /nuxeo-audit
/_delete_by_query
ISM/ILM delete actions on this index
We understand this is compatible with the fact that, by default, OpenSearch does not systematically log all delete operations at HTTP level if security/audit logging is not enabled.
The very high value of deleted documents on this index suggests that many entries were logically deleted (tombstoned in Lucene segments), not lost because of a shard or segment corruption.
In case of a physical loss (corrupted segment, lost shard), we would rather expect missing data without being counted as “deleted documents”, which is not what we see.
The index nuxeo-audit itself appears to be continuous since mid-May 2024:
creation_date is fixed around 2024-05-15,
cluster recovery information does not show any later SNAPSHOT restore or index recreation for this index.
This indicates that the history was modified inside this same index, not replaced by an older snapshot.
From all this, our current conclusion is that the loss of audit history before ~26 May 2024 is most likely due to a logical delete operation on OpenSearch (for example via _delete_by_query or a script/tool built on top of it), rather than a low-level corruption issue.
At this stage, we are really trying to identify the root cause as precisely as possible:
We have no ILM/Curator/ISM policy configured to purge this index.
We do not have old snapshots anymore to replay the index state month by month as you suggested.
We only know that:
the migration ES → OS with _reindex happened in May 2024,
the audit history was still visible for some documents on 10 October 2024,
and today, almost all events prior to that period have disappeared and are counted as deleted documents.
Do you see any other possible scenario that could lead to such a massive increase in docs.deleted focused on old data (pre-migration), besides:
a manual/automated _delete_by_query (or similar), or
a misconfigured maintenance job/tool acting on the index?
Any additional hint or angle of investigation you could suggest would be very helpful for us.
One additional observation about the current state of the nuxeo-audit index:
By comparing two Index Management screenshots taken about 15 days apart, we see that:
the total documents value stayed in the same order of magnitude (from 2.93B to 3.07B),
but the deleted documents counter decreased, from about 77,970,282 deleted docs to 64,042,313.
Do This means that some deleted documents are being gradually purged? .
@Riadh Yes, As background segment merges run, those segments are compacted and the deleted docs are dropped, so the “deleted documents” figure naturally decreases over time. That’s internal Lucene housekeeping, not a new delete event, and it doesn’t restore any data.
Regarding other possibilities, no, I can’t think of any other factors that would result in deletion of documents.