Hello everyone,
We are currently using OpenSearch 2.19.3 running on RHEL 8 virtual machines, with Opensearch deployed inside Podman containers. We use own Opensearch builds with UBI base. Our data ingestion pipeline is handled by Logstash. We are about to update on Opensearch 3.
We use this logstash: opensearchproject/logstash-oss-with-opensearch-output-plugin - Docker Image
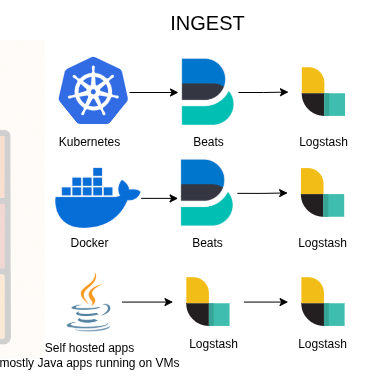
We ship documents from Kubernetes using Beats: auditbeat, filebeat, heartbeat, and metricbeat.
These Beats feed into Logstash, which also processes logs from some Dockerized applications.
Additionally, several RHEL 8 VMs with applications send logs directly to Logstash.
We rely on Logstash because we need multiple inputs (beats, TCP), as well as processing filters like grok, ECS compatibility, mutate, and enrichment.
Our ingest:
Store enriched logs for 3 months.
Perform aggregations on the data for up to 2 years.
Dashboards are built on keywords and numeric data.
Alerting is configured based on document counts and difference between buckets.
Are there any recommendations or best practices to improve this architecture? Something new that we should try in Opensearch 3?
Is Logstash still fully supported as an output for OpenSearch 3?
Are there any updated or official Docker images build on UBI for OpenSearch 3 that you would recommend?
Thanks in advance for your advice!
Dhruv
December 3, 2025, 8:18pm
2
I think Logstash 9 should be supported to OpenSearch 3.x . I haven’t fully tested everything but my Initial test showed it works once you install the logstash-output-opensearch plugin and set xpack.monitoring.enabled: false and pipeline.ecs_compatibility: disabled.
we’re using logstash 7.x for OpenSearch 3.2 without issue and in progress of moving to Logstash 9.x
heemin
December 8, 2025, 11:58pm
3
@vnovotny98 Did you consider Fluentbit + DataPrepper instead of alien family members (*beats/logstash)? They are Opensearch friendly, probably more efficient also.
@heemin He probably means replacement of base image in container (amazon linux by default) with RHEL UBI base image. We also do this, works fine.
I considered Fluentbit + DataPrepper instead of alien family members (*beats/logstash)?
But I have a problem that I need inputs that DataPrepper hasn´t covered.
I created issue in 2023.
opened 02:32PM - 20 Jan 23 UTC
enhancement
plugin - source
I am in charge of collecting application logs. I have java applications that has… logging.config written in logback.xml.
Loback.xml - part of sending logs to logstash looks like:
```
<appender name="STASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>node1:port</destination>
<destination>node2:port</destination>
<destination>node3:port</destination>
<ssl>
<trustStore>
<location>file:/xxx/logstash.truststore</location>
<password>pw</password>
</trustStore>
</ssl>
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<customFields>{"...."}</customFields>
</encoder>
</appender>
```
With these settings on java APP server. The application sends data to logstash and Logstash is set to Server and on input has: TCP source plugin.
Can you add these feature to DataPrepper, so I can use DataPrepper instead of Logstash? I dont know another way to transmit logs to logstash from my app machine.
I am looking for alternative config that I have in Logstash OSS with OpenSearch Output Plugin:
```
input {
tcp {
mode => "server"
host => "IP"
port => "port"
ssl_enable => "true"
ssl_cert => "crt"
ssl_key => "key"
ssl_key_passphrase => "PW"
ssl_verify => "false"
ssl_cipher_suites => ['TLS_AES_256_GCM_SHA384', 'TLS_AES_128_GCM_SHA256', 'TLS_CHACHA20_POLY1305_SHA256', 'TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384', 'TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384', 'TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256', 'TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256', 'TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256', 'TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256', 'TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384', 'TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384', 'TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256', 'TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256']
ssl_supported_protocols => ['TLSv1.2', 'TLSv1.3']
codec => "json_lines"
tags => "ssl_TCPinput"
}
}
filter {
if [LogType] == "TrxPersist" {
mutate { add_tag => "trx_log" }
}
else if [LogType] == "TrxPostProc" {
mutate { add_tag => "trx_time" }
}
if [appname] == "INT_EDDIE" {
mutate { add_field => { "[@metadata][target_index]" => "eddie-int" } }
}
}
output {
if [enviroment] == "integration" {
if [appname] == "INT_EDDIE" {
opensearch {
hosts => ["IP:9200"]
ssl => true
ssl_certificate_verification => false
user => "user"
password => "pw"
index => "%{[@metadata][target_index]}-temporary-%{+YYYY-MM-dd}"
manage_template => false
}
}
else {
opensearch {
hosts => ["IP:9200"]
ssl => true
ssl_certificate_verification => false
user => "user"
password => "pw"
index => "trash-int-%{+YYYY.MM.dd}"
manage_template => false
}
}
}
else {
opensearch {
hosts => ["IP:9200"]
ssl => true
ssl_certificate_verification => false
user => "user"
password => "pw"
index => "trash"
manage_template => false
}
}
}
```
I had conversation on forum before this report: https://forum.opensearch.org/t/logstash-conf-converter-to-data-prepper/12082/3
He probably means replacement of base image in container (amazon linux by default) with RHEL UBI base image. We also do this, works fine. - Yes, that’s it!